


Cluster computing is the practice of linking multiple servers, or nodes, so they function as a single, unified system. Instead of relying on one machine, a cluster distributes workloads across many interconnected nodes, each contributing compute power, memory, and storage. In the cloud, this approach is central to AI: Clusters of GPU servers make it possible to train massive models, scale inference globally, and balance demand across users in real time.
By combining parallelism, tightly coupled communication, orchestration, and intelligent workload distribution, cluster computing can turn thousands of individual GPUs into the equivalent of a single supercomputer, one that is elastic, fault-tolerant, and purpose-built for AI at scale.
Cluster computing vs. traditional computing
In traditional computing, one server handles one workload. When performance limits are reached, the only option is to upgrade or replace that machine. Cluster computing changes the model by pooling resources from many servers into a single system that can be scaled horizontally. This difference is especially important for AI workloads, where one node alone cannot handle the data volumes or model sizes involved.
Cluster computing vs. supercomputing
Cluster computing refers broadly to linking multiple servers together to function as a single, more powerful system. It’s the backbone of modern AI infrastructure, making it possible to scale beyond the limits of any individual machine. Supercomputing describes a reason you may create a cluster: to move far beyond the limits of an individual machine, and enable the elements of the cluster to work together with high performance, representing the most advanced and most resource-intensive form of computing.
Supercomputers are essentially specialized clusters that push scale to the extreme, often harnessing thousands of GPUs (>1K) in tightly coupled networks with ultralow-latency interconnects. They’re designed for workloads that demand the absolute highest levels of throughput and parallelism, such as training trillion-parameter foundation models, running climate simulations, or conducting particle physics experiments.
While both approaches rely on the same principle of distributed computing, the distinction lies in scale and specialization. Clusters can be built incrementally to meet the needs of most enterprises, balancing cost, flexibility, and performance. Supercomputers, by contrast, are purpose-built systems optimized for peak performance at massive scale. They are often backed by governments, research institutions, or hyperscalers with the resources to support them.
Key components of an AI cluster
To understand how cluster computing works in the cloud, it helps to break down the essential building blocks. Every AI cluster is made up of individual servers working together, but it’s the way these parts are orchestrated that transforms them into a single high-performance system. From the nodes that provide raw compute power to the load balancers that keep workloads running smoothly, each component plays a critical role in enabling AI at scale.
Node: A node is a single server within the cluster. Each one typically contains CPUs for general-purpose processing and GPUs for parallel computation, local memory, and storage. Nodes can vary in size and configuration, but when connected, they pool their resources to tackle workloads too large for any one server to handle. In AI clusters, GPU nodes are the backbone. They accelerate training, handle massive datasets, and power real-time inference.
Cluster: The cluster is a complete system formed by linking many nodes together. Orchestration software manages the cluster so that all nodes operate as one cohesive environment. This makes the entire collection of machines appear to the user as a single powerful compute resource rather than a set of separate servers. Clusters allow AI teams to scale from a few GPUs for development to thousands for foundation model training.
Load balancer: The load balancer acts as the traffic controller for the cluster. It distributes incoming requests and computational tasks across available nodes, ensuring no single server becomes a bottleneck. By balancing workloads dynamically, it keeps performance consistent, prevents downtime, and maximizes the overall efficiency of the cluster.
Together, these components transform a group of independent servers into a unified, resilient, and scalable system capable of meeting the extreme demands of modern AI.
How cluster computing works
At its core, cluster computing works by dividing a large problem into smaller tasks that can be processed in parallel. Orchestration software coordinates this distribution, sending jobs to available nodes and then stitching results back together. Networking infrastructure keeps nodes in constant communication so that they behave as one synchronized system rather than a collection of separate servers.
For AI specifically, this means that a massive training dataset can be split across many GPU nodes, each handling a portion of the computation. As nodes complete their tasks, the cluster aggregates the results, updates the model, and then redistributes new workloads in a continuous cycle.
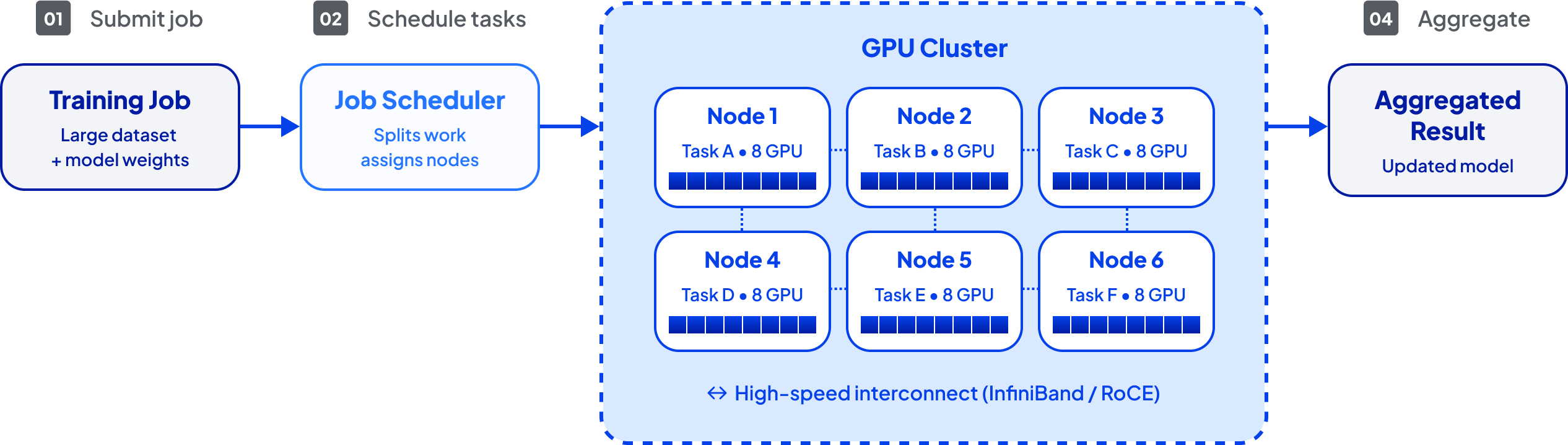
Key benefits of cluster computing for AI
AI workloads are some of the most demanding in modern computing, requiring enormous processing power, seamless scaling, and continuous availability. Cluster computing meets these challenges by combining many GPU-equipped servers into a single unified system. This architecture doesn’t just add raw horsepower; it creates flexibility, resilience, and efficiency that single machines or isolated servers can’t match.
- Massive scalability: Clusters can expand horizontally by adding more nodes, which means they grow in step with the size of datasets and the complexity of models. This makes it possible to train foundation models with billions, or even trillions, of parameters, something no single server could achieve.
- High availability: Fault tolerance must be built into the cluster design so that slow or faulty nodes can be automatically replaced, eliminating the time teams would otherwise spend manually diagnosing and swapping hardware. For AI, this reliability is critical, as downtime can stall experiments and delay production timelines.
- Performance at scale: GPU clusters bring together hundreds or thousands of accelerators that work in parallel. This accelerates both training and inference, reducing the time it takes to train massive models from months to weeks, or even days, and delivering faster responses for real-time applications, such as speech recognition or autonomous navigation.
- Resource flexibility: Not all workloads are equal in size or urgency. Job schedulers dynamically allocate resources to match demand, whether that’s devoting more GPUs to a large training job or spreading smaller inference tasks across nodes. This flexibility helps optimize costs while keeping performance consistent.
In short, cluster computing delivers the speed, resilience, and adaptability that AI workloads demand, turning the impossible into the practical and the experimental into the deployable.
Common challenges with cluster computing
While cluster computing unlocks extraordinary scale and performance, it also comes with a new layer of complexity. Unlike single servers, clusters are distributed systems that rely on constant coordination across many moving parts. That coordination is powerful, but it can also create bottlenecks, raise costs, and demand expertise that not every team has in-house. Recognizing these hurdles is key to planning an AI strategy that balances ambition with practicality.
Networking overhead
Every node must communicate with all others to enable coordinated computation. If the interconnects between nodes are too slow or too congested, data transfer becomes a bottleneck, limiting performance no matter how many GPUs are available. For large-scale AI training, this can mean wasted resources and longer training times.
Resource management
Deciding which jobs run on which nodes isn’t as simple as flipping a switch. Developers use job schedulers assign workloads, monitor performance, and reallocate resources on the fly. This requires both software sophistication and operational know-how, especially as the cluster grows.
Scaling costs
While clusters can scale almost infinitely by adding nodes, those nodes come with real expenses. GPU servers can be costly to acquire and maintain, and as workloads grow, energy and cooling demands rise sharply. As workloads expand, organizations are challenged to balance raw compute needs with financial realities and sustainability goals. The focus is shifting from scaling at any cost to scaling intelligently, and finding solutions that deliver the required performance while keeping budgets and environmental impact in check is a top priority.
Specialization
Running AI workloads efficiently often requires optimization of both hardware and software of the cluster. GPU memory allocation, interconnect bandwidth, and scheduling policies all have to be optimized for the specific workload. Without this specialization, performance can lag far behind the cluster’s theoretical capabilities.
In short, clusters are incredibly powerful but not plug-and-play. They demand careful planning, skilled management, and ongoing optimization to deliver their full potential for AI.
How AI clusters are used in practice
The true impact of cluster computing becomes clear when you look at how it powers real-world AI applications. By pooling GPU resources into unified cloud clusters, organizations can process enormous datasets, train increasingly complex models, and deploy them at scale, all with levels of speed and efficiency that a single server could never achieve.
Generative AI
Foundation models with billions or even trillions of parameters rely on GPU clusters for both training and inference. Clusters make it possible to shorten training cycles from months to weeks and to serve real-time responses to millions of users simultaneously, whether that’s generating text, images, or video.
Healthcare
Medical AI applications demand not just accuracy and reliability, but also rigorous privacy protections. Clusters enable large-scale training of clinical language models, imaging diagnostics, drug discovery, and speech-to-text systems for electronic health records, all while ensuring sensitive patient data remains secure. With features such as tenant isolation, cluster computing can also help safeguard sensitive patient data while still supporting collaborative research and development. The ability to process massive volumes of data quickly, without compromising compliance or confidentiality, helps healthcare workers make faster, more informed decisions.
Autonomous systems
Self-driving vehicles, drones, and robotics all rely on split-second perception and decision-making. GPU clusters provide the compute power to train these perception models in highly detailed simulations and then support inference workloads in production, where latency is critical.
Computer vision
From facial recognition and video analytics to industrial inspection and smart city applications, computer vision workloads push GPU clusters to their limits. Training requires processing vast numbers of high-resolution images and videos, while deployment often demands real-time inference at scale. Clusters make it possible to handle both ends of this spectrum, accelerating development of new vision models and powering production systems where speed and accuracy are paramount.
Finance
From climate modeling to particle physics to drug discovery, researchers depend on clusters for large-scale simulations and data analysis. The ability to run highly parallel computations dramatically reduces time-to-insight, turning once impractical experiments into achievable projects.
In each of these domains, AI clusters serve as the backbone that transforms massive computational challenges into practical, scalable solutions, bringing groundbreaking innovation within reach.
The impact of cluster computing in modern AI
Cluster computing has already evolved from a specialized technique to a foundational layer of modern AI infrastructure. Computing that once required significant investment in on-premise hardware and HPC talent is now accessible on demand in the cloud, giving teams of all sizes the ability to experiment, scale, and deploy breakthrough models. By linking thousands of GPU nodes into unified systems, clusters make it possible to process data at unprecedented speeds and bring advanced AI applications into everyday use.
The significance isn’t just technical, it’s strategic. Whether you’re building generative AI products, advancing medical research, or running large-scale simulations, cluster computing provides the flexibility and resilience to turn ambitious ideas into practical results. As demand grows, the organizations that understand how to harness clusters effectively will be the ones driving the next wave of AI innovation.






